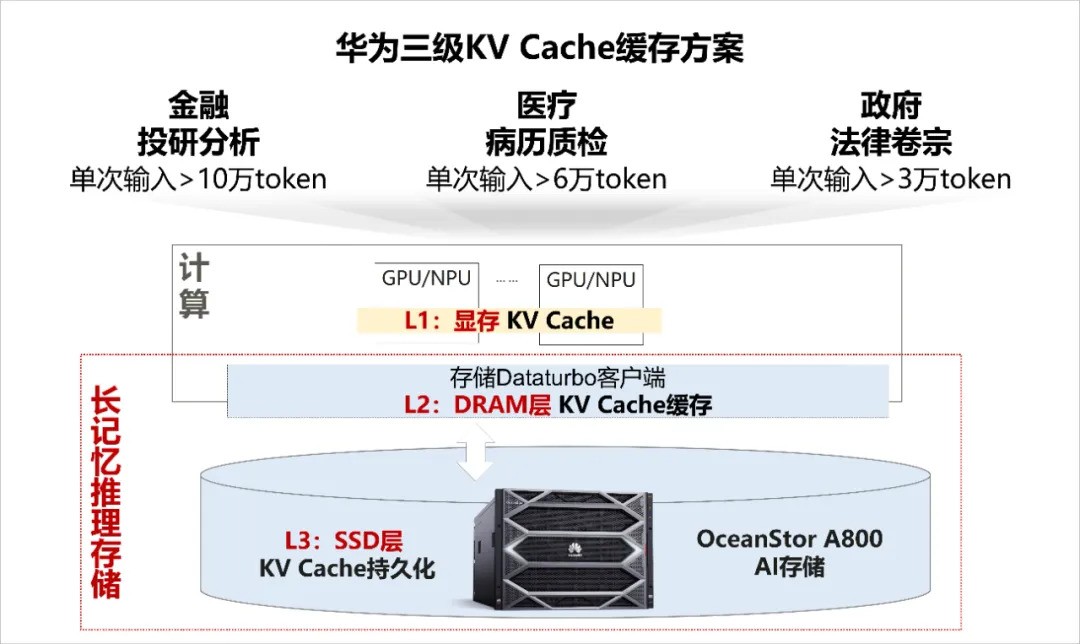
近日,华为OceanStor A800 AI存储通过Unified Cache三级KV Cache缓存方案,使大模型支持超长序列推理;在长序列场景下吞吐提升120%~500%,首Token时延降低90%以上;同时KV Cache命中率达到50%+,大幅减少重复计算,使推理成本降低50%以上,实现大模型推理推得动、推得快、推得省。
华为数据存储产品线闪存领域副总裁严浩指出,随着AI行业化落地加速,在大模型的应用落地过程中出现一些新的挑战。首先,海量的数据接入难,企业价值数据无法高效利用,制约了模型开发质量与效率;其次,大模型推理从短序列迈向长序列,在探索长序列推理应用落地时,存在大模型推理推不动、推得慢、推得贵的问题。
然而,传统数据湖仅支持标量检索,需投入大量人力进行预处理,效率难以满足从传统应用向AI应用转型的需求。构建企业AI数据湖,可实现数据应入尽入,并借助语义级检索能力实现数据交互、数据共享,深度挖掘企业数据价值,进而形成企业统一的数据空间。
随着AI技术的发展,长序列推理在教育、金融、医疗等行业的探索应用日益深入,但在科研助手、信贷审批、病例质检等推理落地场景中存在三大挑战:因长序列超出大模型上下文窗口导致关键信息截断,推理推不动;序列增长使推理并发能力下降,引发响应时间延长,甚至出现服务器繁忙,推理推得慢;长序列处理需要更大的显存容量,服务器扩容增加推理成本,导致推得贵。
业界通过系统化创新解决大模型长序列推理难题,其中主流趋势是采用外置存储分级持久化KV Cache方案,以解决大模型内存能力缺失与扩展问题,从而提升长序列处理能力。
华为OceanStor A800 AI存储通过Unified Cache三级KV Cache缓存方案,使大模型支持超长序列推理;在长序列场景下吞吐提升120%~500%,首Token时延降低90%以上;同时KV Cache命中率达到50%+,大幅减少重复计算,使推理成本降低50%以上,实现大模型推理推得动、推得快、推得省。
目前,该方案已在金融财报分析、会议纪要、法律卷宗分析等场景应用落地,有效解决了客户在长序列推理遇到的痛点问题。
本文属于原创文章,如若转载,请注明来源:华为AI存储突破长序列推理瓶颈https://stor.zol.com.cn/972/9725973.html